This project presents an Arabic spelling correction system built using a sequence-to-sequence transformer model (T5) fine-tuned specifically for noisy text. To train the model, I scraped over 100,000 high-quality articles from the Youm7 news website, which served as clean reference data.
I then generated synthetic noisy versions by injecting common spelling and typing errors to simulate real-world mistakes. The final model was trained on this parallel dataset to learn effective correction patterns.
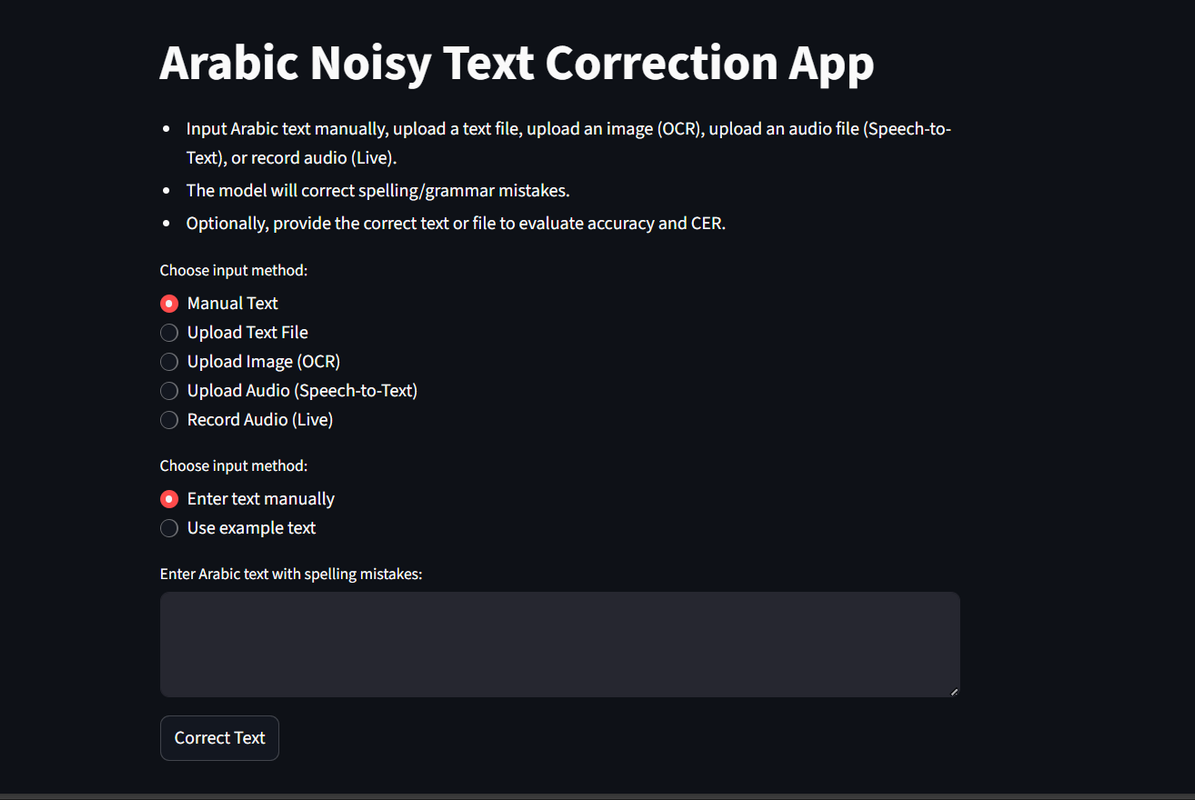
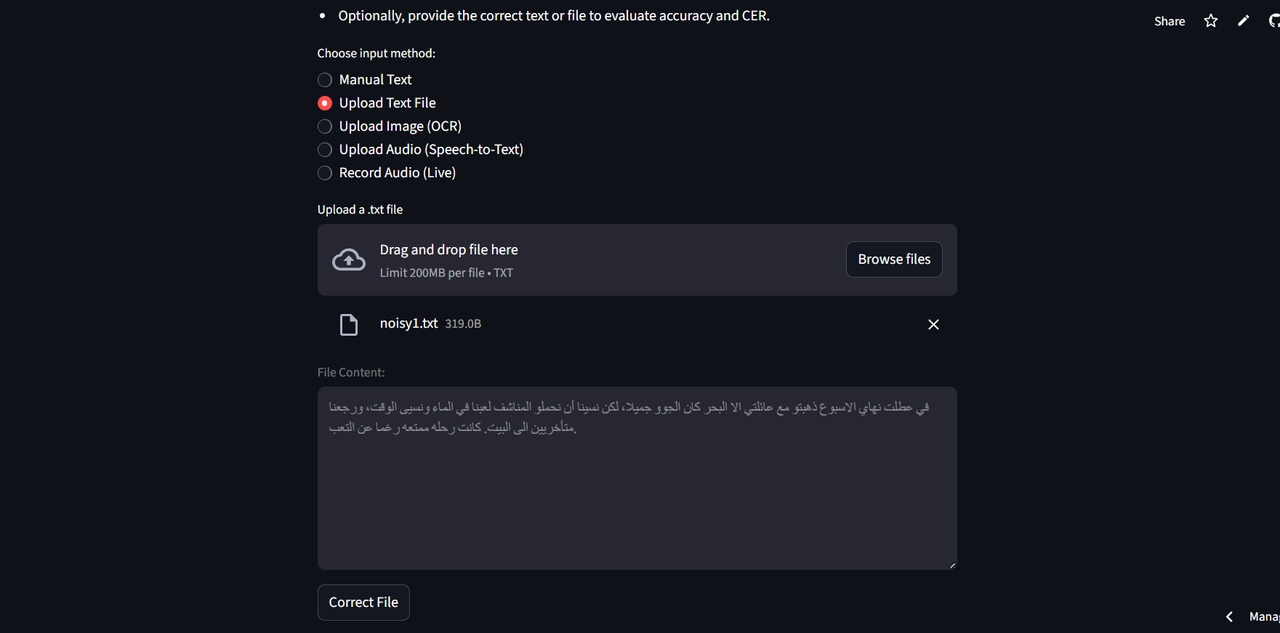
The system is deployed as a Streamlit web application and supports multiple input methods: manual text input, text file upload, OCR from images, and speech-to-text from audio recordings.
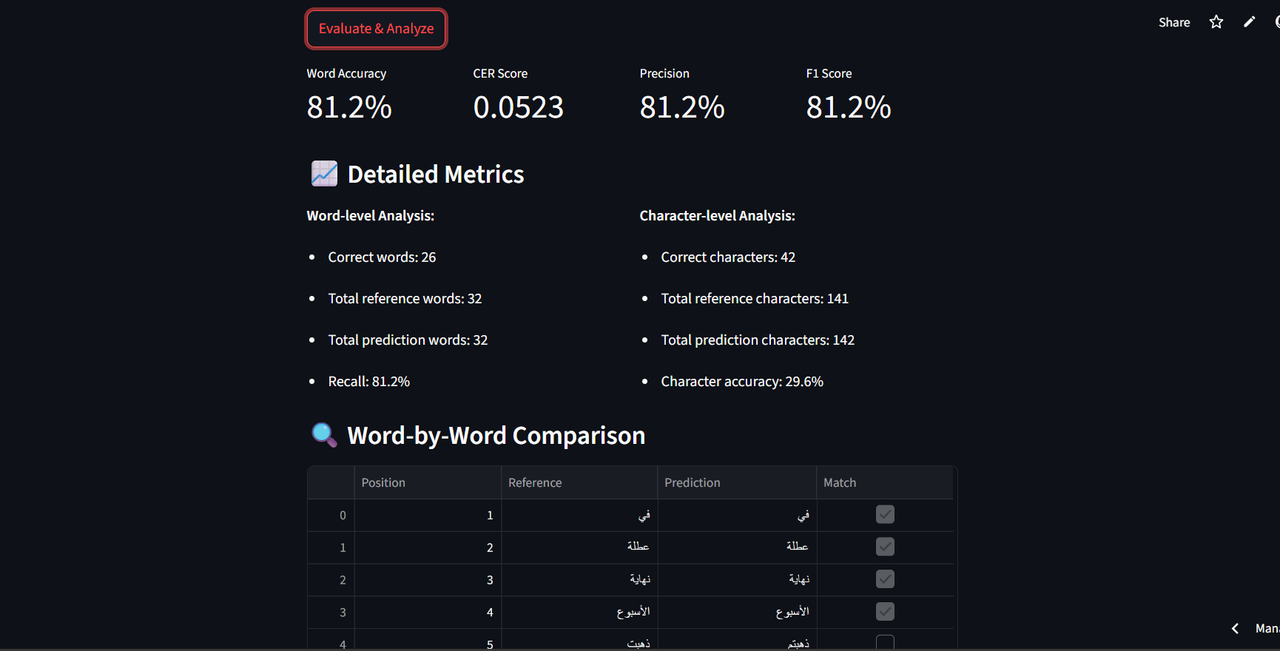
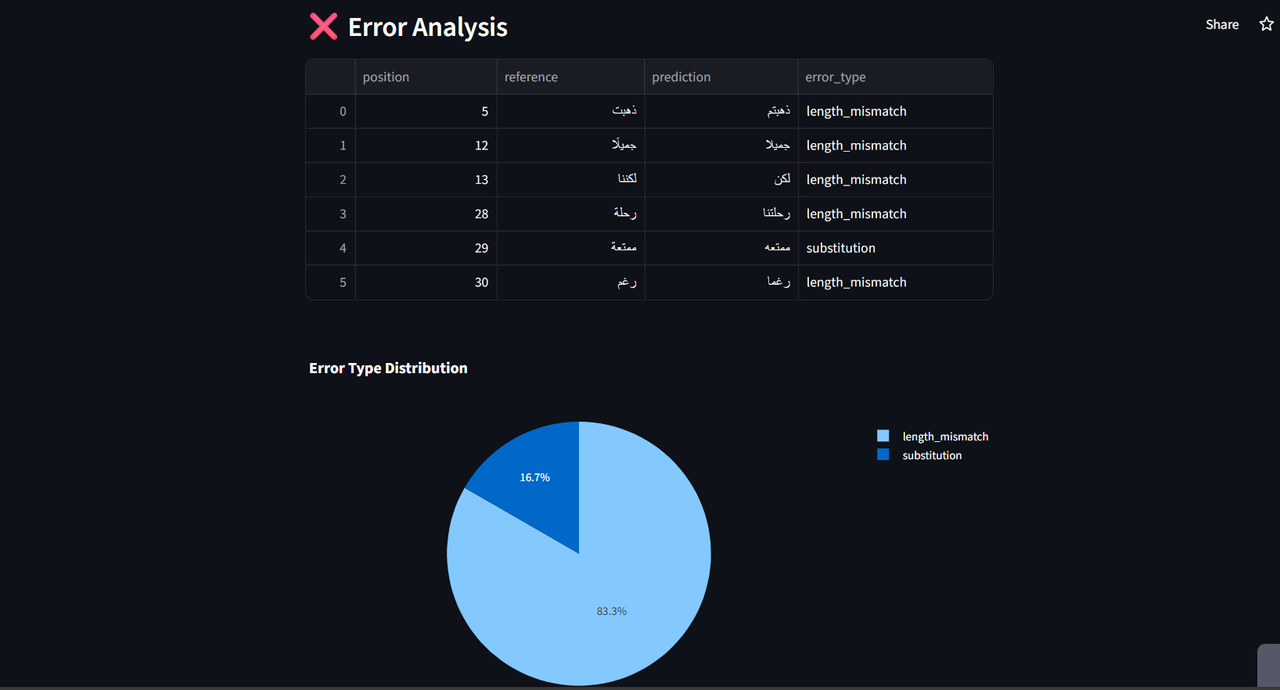
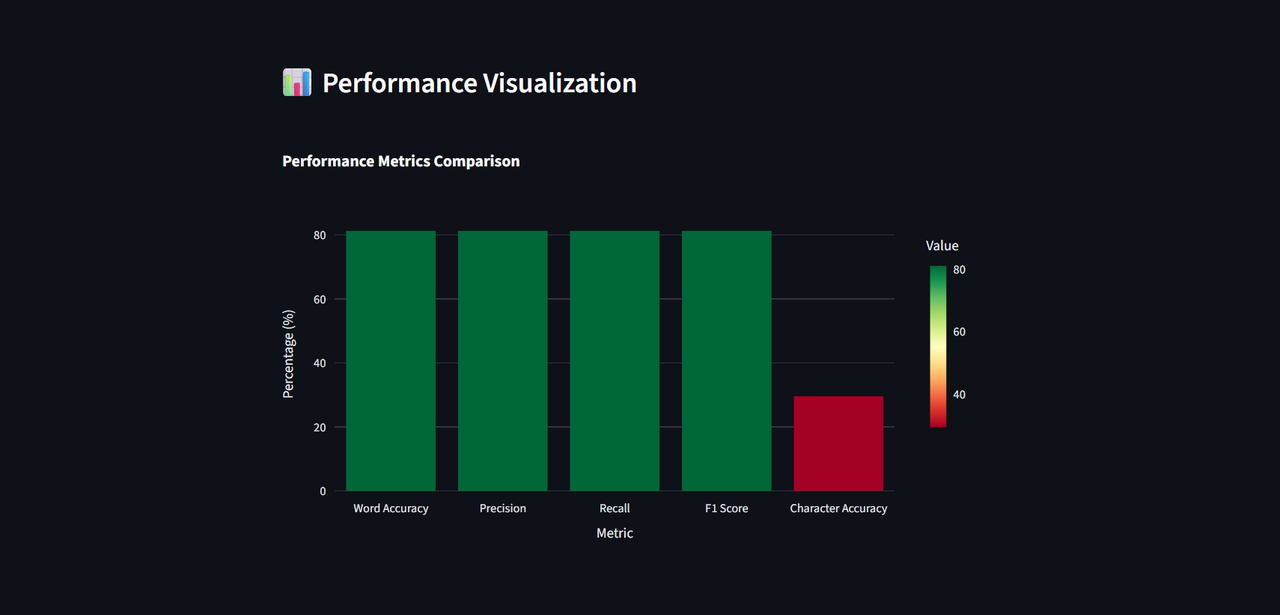
It offers real-time correction output along with an Advanced evaluation metrics including accuracy , character error rate (CER), precision, recall, and F1 score.